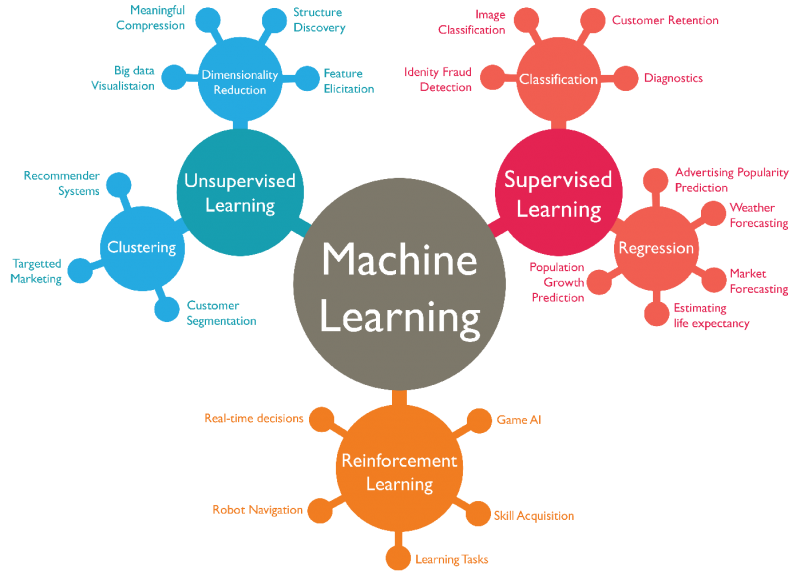
强化学习是机器学习的分支之一,但是又区别于常见的机器学习(例如上图监督学习和无监督学习)。监督学习和无监督学习需要静态的数据,不需要与环境交互,数据输入到相关函数训练就行。而且对于有监督学习和无监督学习来说,有监督学习强调通过学习有标签的数据,预测新数据的标签,无监督学习更多是挖掘数据中隐含的规律。
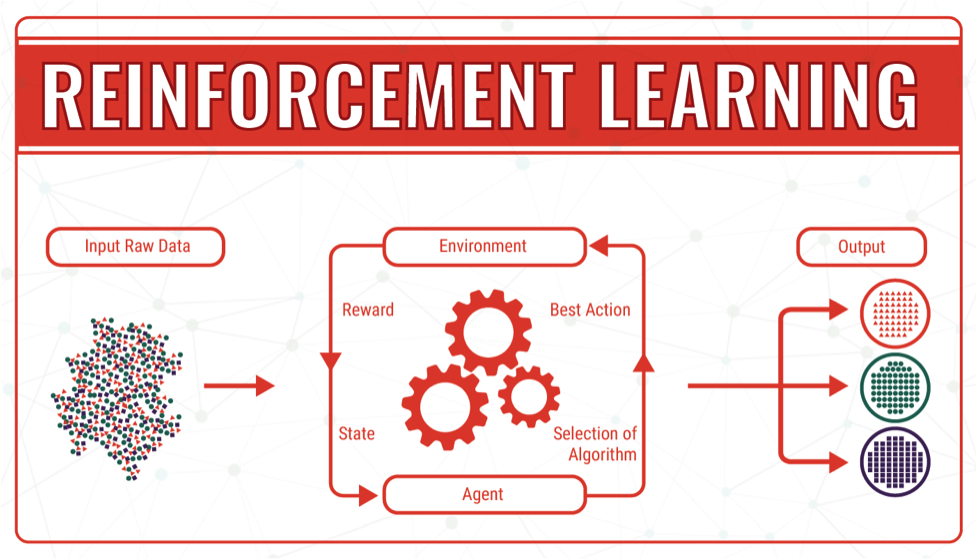
而强化学习的学习过程与其他机器学习不同,根据上图,智能体(agent)在进行某个任务时,首先与环境(environment)进行交互,产生新的状态(state),同时环境给出奖励(reward),如此循环下去,agent和environment不断交互产生更多新的数据。强化学习算法就是通过一系列动作(action)策略与environment交互,产生新的数据,再利用新的数据去修改自身的动作策略,经过数次迭代后,agent就会学习到完成任务所需要的动作策略。
如果一个问题可以被描述成或转化成序列决策 (sequential decision making) 问题,可以构造出强化学习需要的状态 (state)、动作 (action)、奖励 (reward) 等元素的时候,这个问题就可能用强化学习解决。笼统地说,如果一个问题是关于设计某种“策略”,那么强化学习就有可能发挥作用,自动化并且优化这些策略。
深度学习是机器学习中一种基于对数据进行表征学习的方法。深度学习具有较强的感知能力,但是缺乏一定的决策能力;而强化学习具有决策能力,对感知问题束手无策。因此,将两者结合起来可以做到优势互补,为复杂系统的感知决策问题提供了解决思路。
Google的DeepMind在2013年和2015年发表了著名的论文“Play Atari with Deep Reinforcement Learning”和“Human-level control through deep reinforcement learning”,一个结合深度学习(DL)技术和强化学习(RL)思想的模型Deep Q-Network(DQN),在Atari游戏平台上展示出超越人类水平的表现。自此以后,结合DL与RL的深度强化学习(Deep Reinforcement Learning, DRL)迅速成为人工智能界的焦点。开启了深度学习和强化学习相结合的“深度强化学习”的时代。
Bridgewater的创始人Ray Dalio在《原则》一书说过,投资是一个反复的过程。你下赌注,失败了,学到新东西,然后再试一次。 在这个艰难的过程中,我们可以通过不断的反复试验来改进自己的决策。 投资问题正是一个序列决策问题,可以利用深度强化学习来解决。在投资交易中,金融environment的定量描述的规模可能很大甚至是连续的,action可能产生长期作用,不能被其他监督学习方法直接衡量,交易action可能影响当前的市场状况。这些特点决定了我们可以采用深度强化学习来进行投资决策。
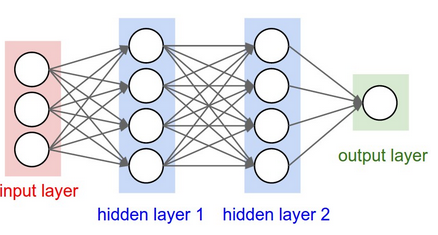
我们可以使用Keras来实现简单神经网络,其结构如上图所示。我们可以将神经网络视为一种近似将输入映射到输出的黑盒子算法。下面的代码创建了一个空的神经网络模型。 我们在输出层中设置有3个节点,来代表不交易,买入(包含long)和卖出(包含short)三种action。
# Neural Net for Deep Q Learning
# Sequential() creates the foundation of the layers.
model = Sequential()
# 'Dense' is the basic form of a neural network layer
# Input Layer of state size(4) and Hidden Layer with 24 nodes
model.add(Dense(units=24, input_dim=self.state_size, activation="relu"))
# Hidden layer with 12 nodes
model.add(Dense(units=12, activation="relu"))
# Hidden layer with 6 nodes
model.add(Dense(units=6, activation="relu"))
# Output Layer with # of actions: 3 nodes (sit, buy, sell)
model.add(Dense(self.action_size, activation='linear'))
# Create the model based on the information above
model.compile(loss='mse',
optimizer=Adam(lr=self.learning_rate))
我们利用常用的Deep Q Network (DQN) 算法来进行策略优化,在Keras中,我们将目标函数定义如下
target = reward + gamma * np.amax(model.predict(next_state))
agent将首先按一定比例随机选择其行动action,称为“探索率”或“epsilon”。 当agent没有随机决定action时,agent将根据当前状态预测reward选择reward最高的action。 np.argmax()是在act_values [0]中选择三个元素之间的最高值的函数。
def act(self, state):
if np.random.rand() <= self.epsilon:
# The agent acts randomly
return env.action_space.sample()
# Predict the reward value based on the given state
act_values = self.model.predict(state)
# Pick the action based on the predicted reward
return np.argmax(act_values[0])
我们使用sigmoid函数来度量state
# returns the sigmoid
def sigmoid(x):
return 1 / (1 + math.exp(-x))
# returns an an n-day state representation ending at time t
def getState(data, t, n):
d = t - n + 1
block = data[d:t + 1] if d >= 0 else -d * [data[0]] + data[0:t + 1] # pad with t0
res = []
for i in range(n - 1):
res.append(sigmoid(block[i + 1] - block[i]))
return np.array([res])
reward使用每笔交易的损益来度量
# buy and sell rewards, data[t] is the latest price reward = max(data[t] - bought_price, 0) # short and long rewards reward = max(short_price-data[t], 0)
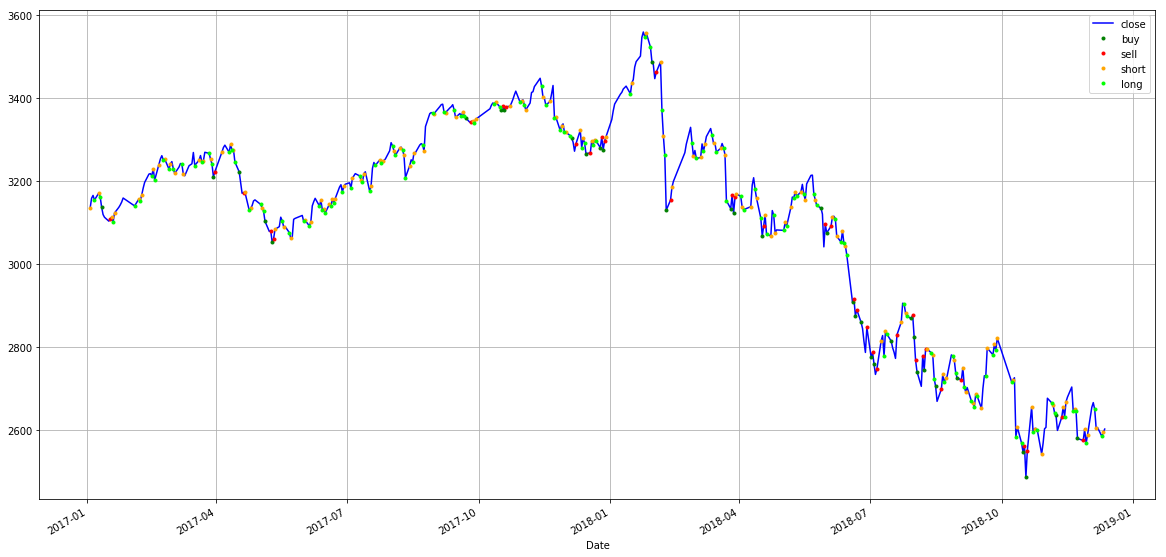
通过组合上述state,reward和action,我们构建了一个最简单的深度强化学习交易算法。我们使用上证指数2010/1/1到2016/12/30的数据作为训练集,使用2017/1/3到2018/12/12的数据作为样本外测试集对算法进行测试,结果显示有35对买入(buy)卖出(sell)交易,122对卖空(short)平仓(long) ,最终盈利617.79点。
... Buy: $2579.48 Sell: $2574.68 | Profit: -$4.80 Short: $2601.74 Long: $2567.44 | Profit: $34.29 Short: $2588.19 Long: $2649.81 | Profit: -$61.62 Short: $2605.18 Long: $2584.58 | Profit: $20.60 Short: $2594.09 -------------------------------- SSE_os Total Profit: $617.79 --------------------------------

评论
 Alex Fang
Alex Fang
Author您的深度强化学习算法很有创意!如能分享您的code,十分感谢!请发到我邮箱,谢谢!
 陈
陈
Author您好,我是一名硕士研究生,目前研究期货投资相关内容。对您的系统很感兴趣,如您能分享您的代码,不胜感激!